tweepy
PythonのTwitter API制御ライブラリtweepyを使って、フォロワー情報をまとめて、JSONに保存してみました。
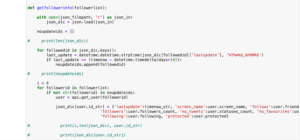
今回はJSONファイルにまとめたフォロワー情報を、CSVファイルに変換し、人間が読みやすくしてみようと思います。
ちなみに今のデータはこんな感じ。
{
"1393442145550278659": {
"lastupdate": "20211103_123209",
"screen_name": "YyM3pI4fMzkYjzj",
"follows": 2776,
"followers": 1687,
"no_tweets": 489,
"no_favourites": 3208,
"following": true,
"protected": false
},
"1158814608": {
"lastupdate": "20211103_123209",
"screen_name": "BowersMateo",
"follows": 4437,
"followers": 4509,
"no_tweets": 3,
"no_favourites": 0,
"following": false,
"protected": false
},
"3169347092": {
"lastupdate": "20211103_123209",
"screen_name": "chp_z",
"follows": 20467,
"followers": 18964,
"no_tweets": 9369,
"no_favourites": 409521,
"following": true,
"protected": false
},
(中略)
{それでは始めていきましょう。
プログラム全体
まずはプログラム全体をお見せします。
import os
import json
import csv
import pandas as pd
json_filename = 'followerlist.json'
csv_filename = 'followerlist.csv'
default_dirpath = r" Pythonプログラムのパス "
json_filepath = os.path.join(default_dirpath, json_filename)
csv_filepath = os.path.join(default_dirpath, csv_filename)
def readjson():
with open(json_filepath, 'r') as json_in:
json_dic = json.load(json_in)
return json_dic
def writecsv(json_dic):
data = pd.DataFrame(json_dic).T
url = []
for i in range(len(data)):
scrname = data.iloc[i]['screen_name']
url.append(f'https://twitter.com/{scrname}')
data['url'] = url
data.to_csv(csv_filepath)
def main():
json_dic = readjson()
writecsv(json_dic)
if __name__ == '__main__':
main()大まかな流れとしてはこんな感じです。
- JSONファイルを読み込む
- 読み込んだJSONファイルをPandasのデータフレームに変換
- ワンクリックでアカウントにアクセスできるようアカウントのURLを追加
- CSVファイルとして書き出す
設定部分
まずは設定部分から。
import os
import json
import csv
import pandas as pd
json_filename = 'followerlist.json'
csv_filename = 'followerlist.csv'
default_dirpath = r" Pythonプログラムのパス "
json_filepath = os.path.join(default_dirpath, json_filename)
csv_filepath = os.path.join(default_dirpath, csv_filename)インポートするライブラリは「os」、「json」、「csv」、「pandas」です。
読み込むJSONのファイル名「json_filename」、書き出すCSVファイル名「csv_filename」、そしてPythonプログラムの場所「default_dirpath」を設定します。
ちなみに「default_dirpath」はこのプログラムをローカル環境で使う場合は「os.getcwd()」でも大丈夫です。
そして「os.path.join(パス1, パス2)」を使って、JSONファイルのパス「json_filepath」、CSVファイルのパス「csv_filepath」を設定します。
JSONファイルを読み込む関数
次にJSONファイルを読み込む関数「readjson」です。
def readjson():
with open(json_filepath, 'r') as json_in:
json_dic = json.load(json_in)
return json_dicここは特に特筆することはないのですが、いつも通りopen関数で読み込み、「json.load(JSONデータ)」で辞書形式に変換します。
その辞書形式にしたデータをreturnで返します。
データの修正とCSVファイルの書き出し
次の関数「writejson」で読み込んだJSONファイルを修正し、CSVファイルとして書き出していきます。
def writecsv(json_dic):
data = pd.DataFrame(json_dic).T
url = []
for i in range(len(data)):
scrname = data.iloc[i]['screen_name']
url.append(f'https://twitter.com/{scrname}')
data['url'] = url
data.to_csv(csv_filepath)辞書データをPandasのデータフレームにするには、「pd.DataFrame(辞書データ)」で変換できます。
個人的にこんなに簡単なのかとびっくりした点でもあります。
ただしデータフレームの縦横が、縦に項目、横に各アカウントのデータとなっていたので、最後に「.T」をつけることによって、縦横を変換しています。
ちなみに「.T」を付けずにデータフレームを出力してみるとこんな感じです。
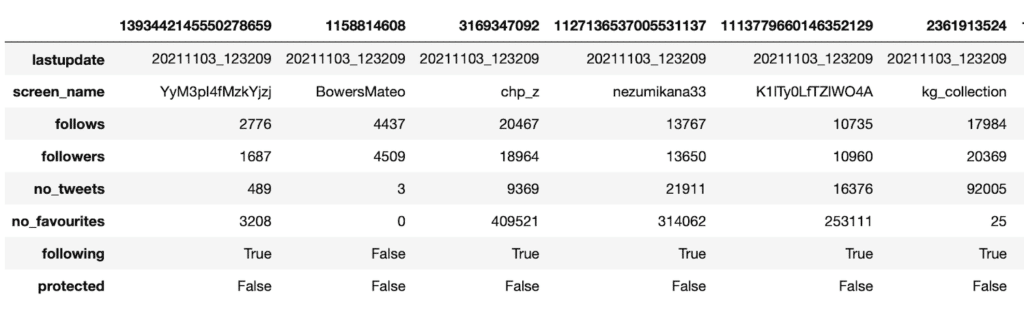
そして「.T」を付けて出力するとこんな感じです。
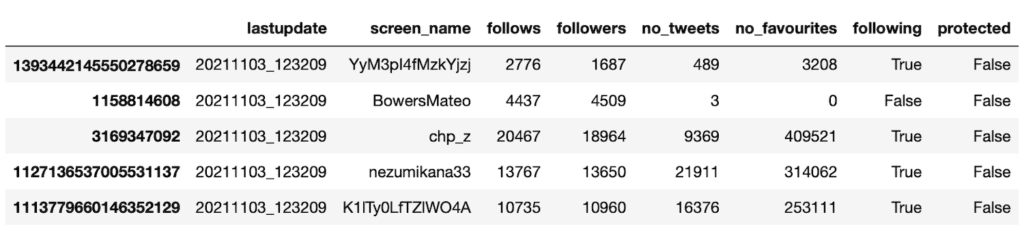
各項目が列となり、それぞれのデータが行となる方が個人的にはしっくりくるので、このように変換しました。
しかしこのまま出力しても、それぞれのアカウントのページにアクセスするのは一苦労です。
ということでアカウント名からアカウントにアクセスするためのURLを作成します。
url = []
for i in range(len(data)):
scrname = data.iloc[i]['screen_name']
url.append(f'https://twitter.com/{scrname}')
data['url'] = url「.iloc[‘行番号’]」で特定のアカウントデータにアクセスでき、さらに「[‘screen_name’]」とすることでアカウント名が取得できます。
それをTwitterのURL「https://twitter.com/」に付加してやれば、そのアカウント名にアクセスするためのURLになります。
そのように作成したURLをリスト「url」に格納したのち、「data[‘url’] = url」とすれば、データフレームに新しい列として追加されます。
Pandasデータフレームの行の追加に関してはこちらの記事もよかったらどうぞ。
あとはPandasのデータフレームをCSVファイルとして書き出すだけです。
data.to_csv(csv_filepath)これも「データフレーム名.to_csv(’書き出すファイルパス’)」だけなので楽ちん。
あとはmain関数部分だけなので、解説は省略します。
そしてこのプログラムを実行して書き出されたCSVファイルはこんな感じです(MacのNumbersで開いています)。
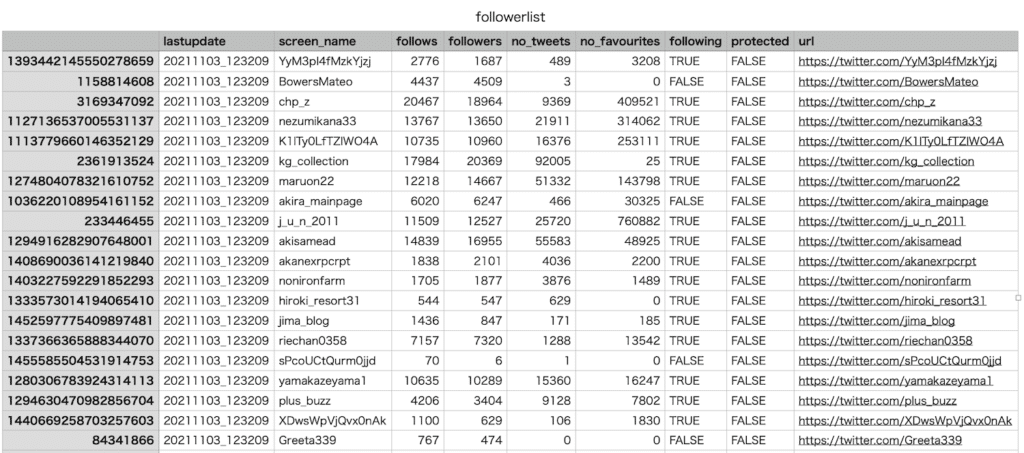
ということでなかなか面白い
せっかくなので次回はちょっとあるアカウントのデータを取得し、フォロワーの傾向を解析してみたいと思います。
ではでは今回はこんな感じで。
コメント