tweepy
前回、PythonのTwitter API制御ライブラリtweepyを使って、フォロワー情報をまとめたJSONファイルをCSVファイルに変換しました。
今回は出力したCSVファイルを使って、データの解析をしていきたいと思います。
それでは始めていきましょう。
CSVファイルの読み込みとpandasのデータフレームへの変換
まずはCSVファイルを読み込み、pandasのデータフレームに変換していきます。
このCSVファイルの読み込みとpandasのデータフレームへの変換はこちらの記事でも解説していますので、良かったらどうぞ。
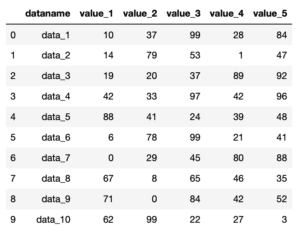
とは言っても難しいことはなく、「pd.read_csv(‘読み込むCSVファイル’)」でCSVファイルの読み込みとpandasのデータフレームへの変換を一度にやることができます。
ということでこんな感じです。
import os
import csv
import pandas as pd
csv_filename = 'followerlist.csv'
default_dirpath = os.getcwd()
csv_filepath = os.path.join(default_dirpath, csv_filename)
data = pd.read_csv(csv_filepath)
data = data.rename(columns={'Unnamed: 0':'id'})
dataまずデータ読み込みに関して、インポートするライブラリは「os」、「pandas」の二つ。
CSVファイルを使いますが、pandasの「pd.read_csv(‘CSVファイル’)」で一気にデータフレーム化しますので、csvライブラリのインポートはいらないようです。
「csv_filename」、「default_dirpath」、「csv_filepath」はそれぞれCSVファイルの名前、Pythonプログラムのパスの取得、CSVファイルのパスを定義しています。
そして「data = pd.read_csv(csv_filepath)」でCSVファイルを読み込み、pandasのデータフレームに変換しています。
ちょっと新しいところは次の行。
data = data.rename(columns={'Unnamed: 0':'id'})もしこの行無しで「data」を表示するとこうなります。
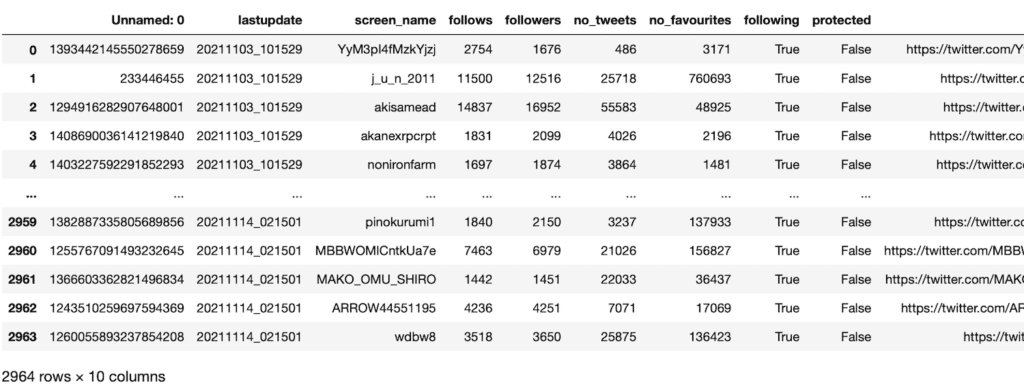
CSVからpandasのデータフレームにした際にインデックス列が追加され、インデックス列として使用していたアカウントIDの列が「Unnamed: 0」になっています。
pandasの場合、数字のインデックスも結構使うので、残しておいた方が得策かなと考え、アカウントIDの列名を「rename」で変更したというわけです。
今回のように列名を変更する場合は、「データフレーム名.rename(columns={’旧カラム名’:’新カラム名’})」です。
ちなみに行名の場合は「データフレーム名.rename(index={’旧行名’:’新行名’})」となります。
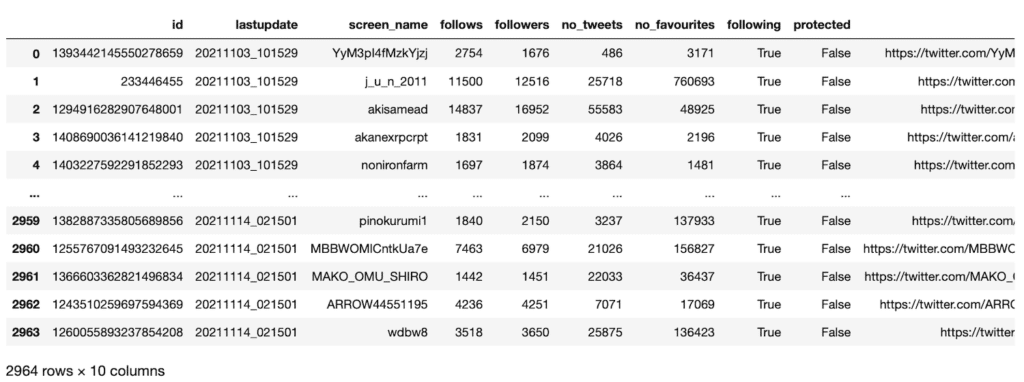
ということで変更するとこんな感じの出力が得られます。
ペアプロットの表示
次にペアプロット(Pairplot)を表示させてみましょう。
ペアプロットに関してはこちらの記事で紹介しています。
数字のデータだけが含まれたデータフレームを入力すると、すべての組み合わせに関して、散布図とヒストグラムを表示してくれる機能です。
こちらのグラフに関してはseabornというライブラリを使用するのと、数字のデータだけのデータフレームにする必要があります。
import seaborn as sns
plots = pd.DataFrame()
plots['follows'] = data['follows']
plots['followers'] = data['followers']
plots['no_tweets'] = data['no_tweets']
plots['no_favourites'] = data['no_favourites']
sns.pairplot(plots)
実行結果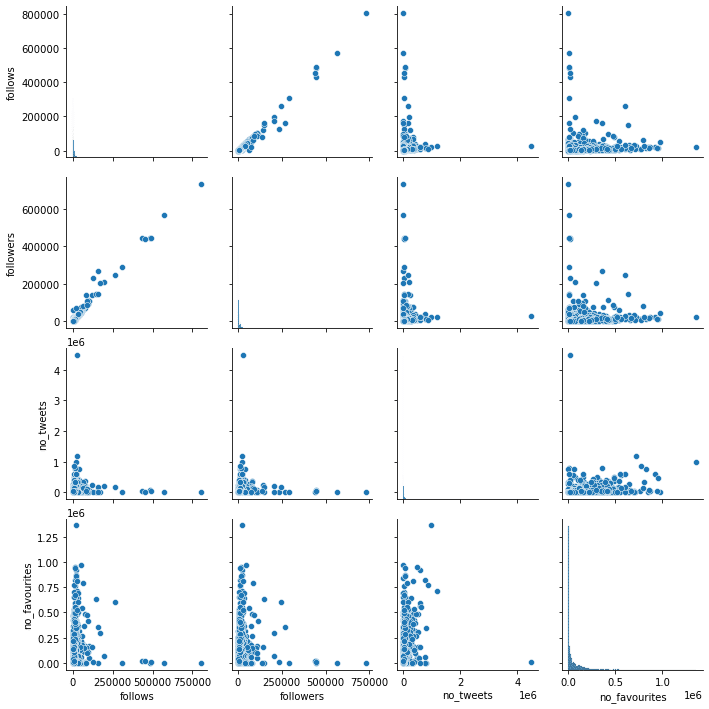
まず「seaborn」ライブラリを「sns」としてインポート。
その後、空のデータフレームを作って、そこに必要なデータを格納します。
plots = pd.DataFrame()
plots['follows'] = data['follows']
plots['followers'] = data['followers']
plots['no_tweets'] = data['no_tweets']
plots['no_favourites'] = data['no_favourites']そして「sns.pairplot(plots)」でペアプロットの表示です。
これでフォロワーの大体の傾向が掴めるので、解析していきましょう。
フォロワーの解析
まず今回データとして含まれるのは、「フォロー数」、「フォロワー数」、「ツイート数」、「いいねの数」の4つのデータです。
そして今回の目的としては、フォロワー数が多いアカウントの傾向を知りたいというのがあります。
その理由としては今後、フォロワー数が多いアカウントを探し出したり、自分のフォロワー数を多くするにはどうしたらいいかという手がかりが欲しいからです。
次に予想です。
予想としては「フォロワー数が多いアカウントは、フォロー数、ツイート数、いいねの数が多い」のではないかと考えられます。
理由としては、フォロー数、ツイート数、いいねの数というのはツイッター上でいうコミュニケーションの量なわけで、コミュニケーションの量が多ければ、フォローしてくれる人が多いだろうということが考えられるからです。
ではそういった目で再度データを見てみましょう。
今回はフォロワー数に注目するので、2段目のデータに注目していきます。
一番左のグラフの「フォロー数vsフォロワー数」を見てみると、右肩上がりのプロットになっています。
つまりフォロワー数が多ければ、フォロー数が多いと言えます。
ただこれには少しデータの質の問題もあり、その点に関しては後ほどお話ししましょう。
次に左から3番目の「ツイート数vsフォロワー数」のグラフを見てみます。
こちらに関しては、一つツイート数がずば抜けて多いものがありますが、そのアカウントのフォロワー数はそれほど多くないということが見受けられます。
またツイート数が少なくても、フォロワー数が多いものもあり、一定の傾向は見えません。
最後に一番右の「いいねの数vsフォロワー数」を見てみましょう。
この「いいねの数」はいいねをされた数ではなく、そのアカウントがいいねをした数であることに注意しましょう。
こちらに関しても一定の傾向は見えません。
ということで「フォロー数vsフォロワー数」のみが関連性があり、他のものは関連性はないと結論づけたいところです。
しかし注意しなければいけないのは、すでにこのアカウントのデータ自体が偏っている可能性です。
実はこのアカウントは、前に作成したプログラムで特定の条件に合うアカウントを抽出し、フォローしているアカウントです。
そしてこのプログラムの中ではある「一定以上のフォロワー数をもち、フォロワー数/フォロー数が一定の範囲内にあるアカウント」を抽出しています。
「フォロワー数/フォロー数が一定の範囲内」、そしてプログラム上では0.9から1.2としているため、フォローしている数が極端に多かったり、フォロワーの数が極端に多いアカウントに関しては積極的にはフォローしておらず、結果、そのようなフォロワーもいないという結果になったにすぎません。
本当はもう少しツイート数やいいねの数と相関があるのかなと思ってやった解析ですが、なかなか思ったようにいかずに残念な結果になってしまいました。
しかしこのように解析して、数値やグラフとして出すことで、体感していたものがよりクリアに理解できるというのは重要なことです。
ということでまた何らかのデータが出てきたら、色々と試していきたいと思います。
ではでは今回はこんな感じで。
コメント