データ解析支援ライブラリPandas
前回はデータ解析支援ライブラリPandasで行や列を追加する方法の基本を解説しました。
今回も行や列を追加する方法ですが、今回はassignとappendというコマンドを用いた方法を解説していきます。
ということで今回もまずは準備から。
使用するデータは、いつものごとく自作のダミーデータ作成プログラムで作ったこちら。
データの読み込みはこんな感じです。
import pandas as pd
df = pd.read_csv("python-pandas-2_data.txt", index_col=0)
df
実行結果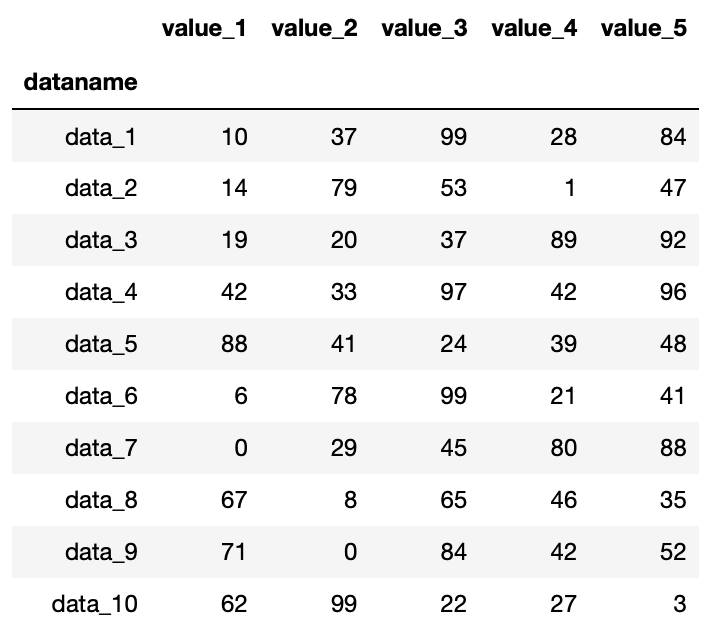
それでは始めていきましょう。
assignで列を追加する方法
まずは列を追加するコマンド「assign」を解説していきます。
今回も先ほどのデータフレームの一番右に平均値を追加してみます。
ということで平均値の計算方法から。
平均値は「.mean()」で計算でき、それぞれの行の平均値を出したいときは、オプションとして「axis=1」(もしくはaxis=”columns”)を追加します。
import pandas as pd
df = pd.read_csv("python-pandas-2_data.txt", index_col=0)
average_data = df.mean(axis=1)
print(average_data)
df
実行結果
dataname
data_1 51.6
data_2 38.8
data_3 51.4
data_4 62.0
data_5 48.0
data_6 49.0
data_7 48.4
data_8 44.2
data_9 49.8
data_10 42.6
dtype: float64この時点ではまだデータフレームに追加されていません。
追加するには、データフレーム名 = データフレーム名.assign(列名 = 追加する列データ)とします。
ということで今回は「df = df.assign(Average = df.mean(axis=1))」となります。
import pandas as pd
df = pd.read_csv("python-pandas-2_data.txt", index_col=0)
df = df.assign(Average = df.mean(axis=1))
df
実行結果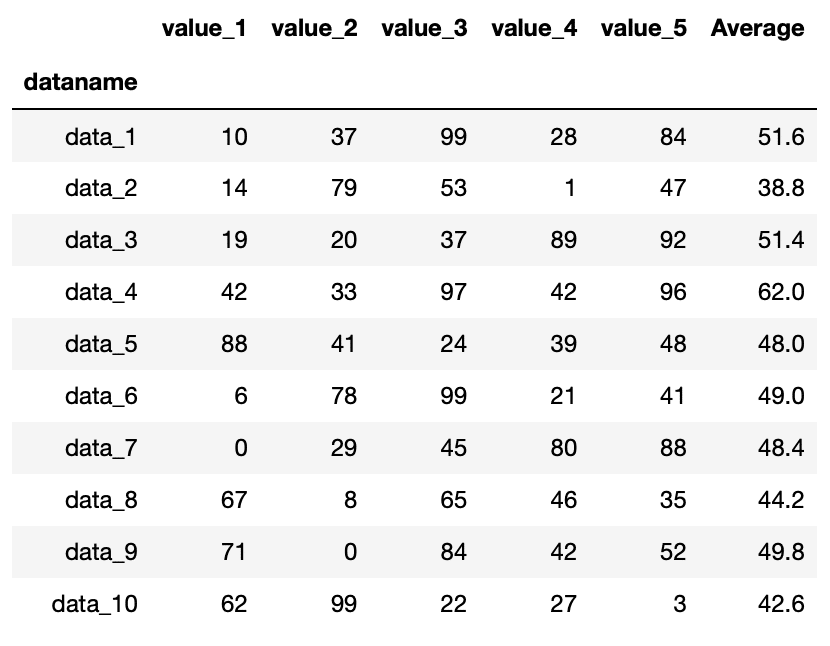
ちなみに最初のデータフレーム名を新規のデータフレーム名にすると上書きではなく、新しいデータフレームを作成してくれます。
ということで新しいデータフレームを「df_average」としてみます。
import pandas as pd
df = pd.read_csv("python-pandas-2_data.txt", index_col=0)
df_average = df.assign(Average = df.mean(axis=1))
df_average
実行結果この状態で新しいデータフレーム「df_average」ではなく、下のデータフレーム「df」 を呼び出してみましょう。
import pandas as pd
df = pd.read_csv("python-pandas-2_data.txt", index_col=0)
df_average = df.assign(Average = df.mean(axis=1))
df
実行結果dfには「Average」の列はありません。
ということで「Average」の列を追加したデータフレームは「df_average」として新規作成されたのが分かりました。
列を特定の値で埋める方法
assignを使う利点として、列を特定の数字で埋めることも可能です。
その場合は、データフレーム名 = データフレーム名.assign(列名 = 埋める数字)とします。
今回は新しく「Zero」という列を作り、「0」で埋めてみましょう。
ということで「df = df.assign(Zero = 0)」を追加してみます。
import pandas as pd
df = pd.read_csv("python-pandas-2_data.txt", index_col=0)
df = df.assign(Zero = 0)
df
実行結果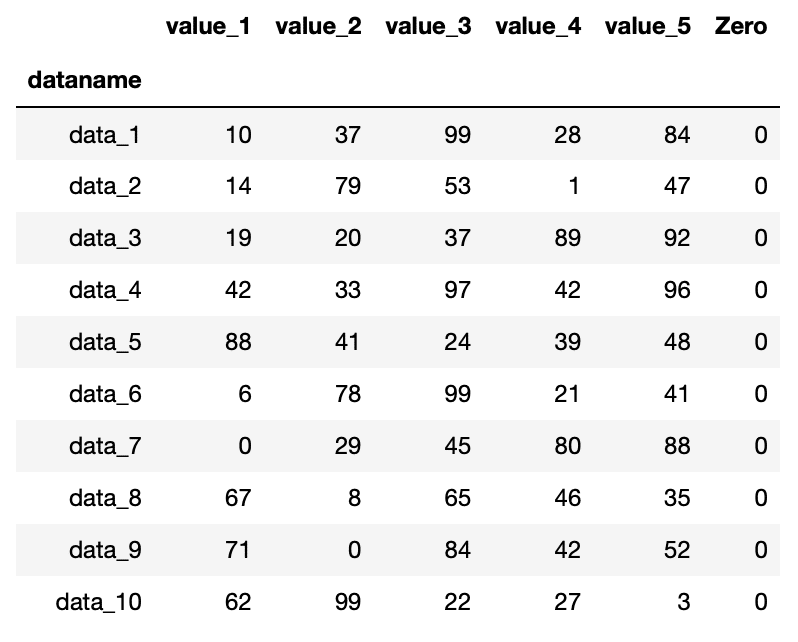
「Zero」という「0」 で埋められた列ができました。
Seriesとは?そしてSeriesの作成方法
次にappendというコマンドを使って列を追加する方法を解説していきたいのですが、この場合は、1行だけのデータフレーム、シリーズ(Seriese)というものを作成する必要があります。
今回使っているデータフレームで言うと、一つのシリーズとしては「data_1」という名前で「10, 37, 99, 28, 84」というデータが格納されている行だと言えます。
逆に「value_1」という名前があり、「10, 14, 19, 42, 88, 6, 0, 67, 71, 62」というデータが格納されている列もまたシリーズの一つだと言えます。
要するに1行、1列の名前を含んだデータがシリーズというわけです。
そのシリーズの作成方法は「シリーズ名 = pd.Series(リスト, インデックス名 or カラム名, name=行名 or 列名)」です。
今回のデータフレームに新しい列を追加するシリーズを作成するにはこんな感じです。
test_series = pd.Series([1, 2, 3, 4, 5, 6, 7, 8, 9, 10], df.index, name=”test”)
追加してみましょう。
import pandas as pd
df = pd.read_csv("python-pandas-2_data.txt", index_col=0)
test_series = pd.Series([1, 2, 3, 4, 5, 6, 7, 8, 9, 10], df.index, name="test")
df = df.assign(test = test_series)
df
実行結果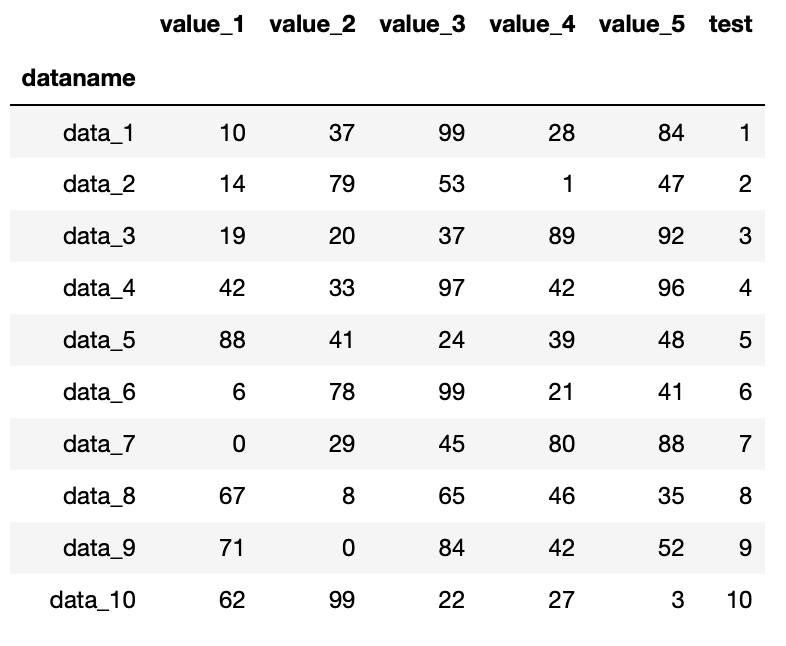
さらに詳細な解説は別の機会にということにしましょう。
ということで行を追加する方法を解説していきます。
appendで行を追加する方法
行を追加するコマンドはappendですが、先ほど解説した通りまずはシリーズが必要となるので、追加する行用のシリーズを作成してみましょう。
行の構成としては「行名 値1 値2 値3 値4 値5」となっており、それぞれの値の名前は「value_1 value_2 value_3 value_4 _value_5」となっています。
ちなみに値の名前は列名なので、df.columnsで取得できます。
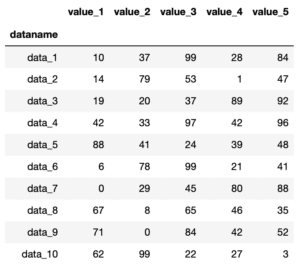
ということで追加する用のシリーズはこんな感じ。
test_series = pd.Series([1, 2, 3, 4, 5], df.columns, name=”test”)
ここでやっと登場するのが、行を追加するコマンドappendです。
追加するには、「データフレーム名 = データフレーム名.append(追加する行データ)」とします。
つまり今回の場合は「df = df.append(test_series)」となります。
これで追加してみましょう。
import pandas as pd
df = pd.read_csv("python-pandas-2_data.txt", index_col=0)
test_series = pd.Series([1, 2, 3, 4, 5], df.columns, name="test")
df = df.append(test_series)
df
実行結果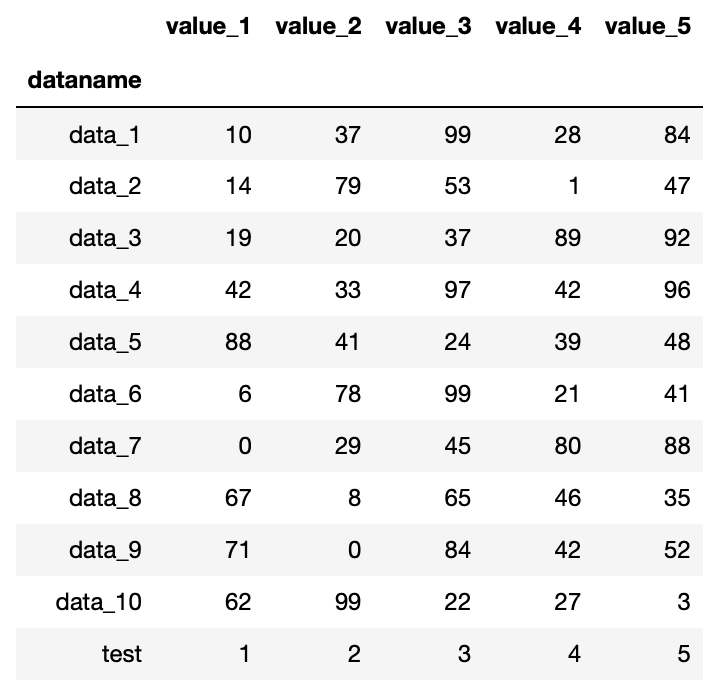
追加できました。
データフレームからの計算値を追加する方法
これまで通り平均値を計算し、新しい行に追加してみましょう。
この場合、行名、列名を省略できます。
つまりそれぞれの列の平均値を集めたシリーズとしては「average = pd.Series(df.mean(), name=”Average”)」となります。
df.mean()が元のデータフレームの列名を含んでいるため、わざわざ列名を指定しなくても認識してくれるようです。
ということで試してみましょう。
import pandas as pd
df = pd.read_csv("python-pandas-2_data.txt", index_col=0)
average = pd.Series(df.mean(), name="Average")
df = df.append(average)
df
実行結果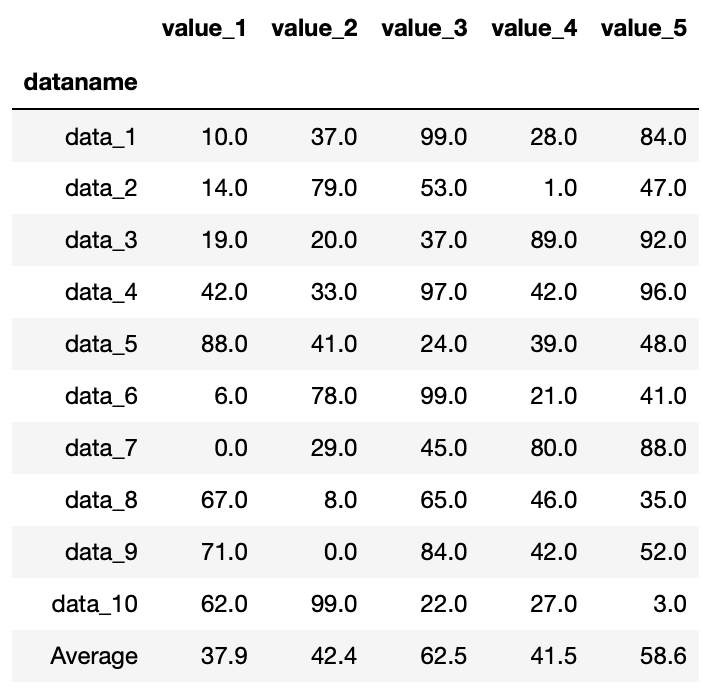
これは逆にそれぞれの行の平均値を新しい列として追加する場合も同じです。
import pandas as pd
df = pd.read_csv("python-pandas-2_data.txt", index_col=0)
average = pd.Series(df.mean(axis=1), name="Average")
df = df.assign(Average = average)
df
実行結果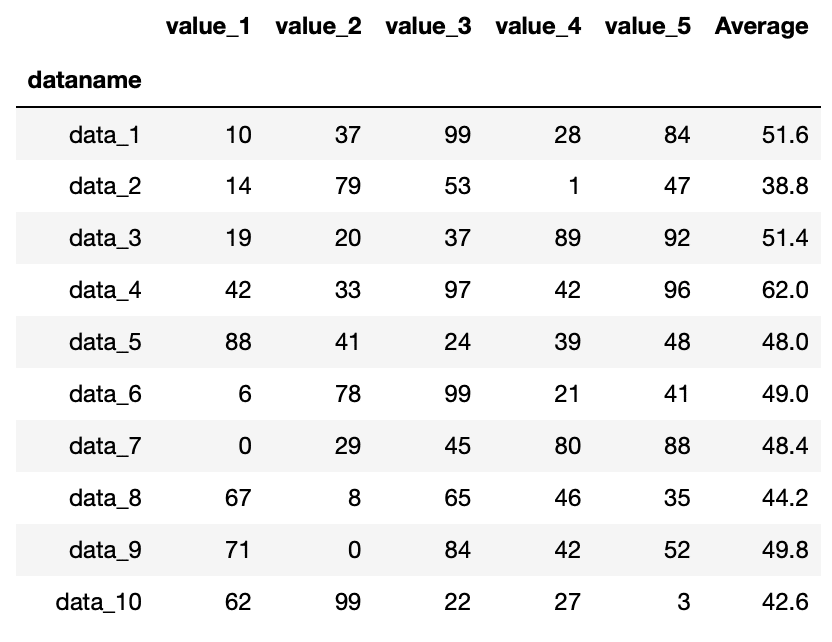
ちなみに行を追加するappendでも、新しいデータフレーム名を使えば、データフレームを上書きではなく、新規作成になります。
import pandas as pd
df = pd.read_csv("python-pandas-2_data.txt", index_col=0)
average = pd.Series(df.mean(), name="Average")
df_average = df.append(average)
df_average
実行結果import pandas as pd
df = pd.read_csv("python-pandas-2_data.txt", index_col=0)
average = pd.Series(df.mean(), name="Average")
df_average = df.append(average)
df
実行結果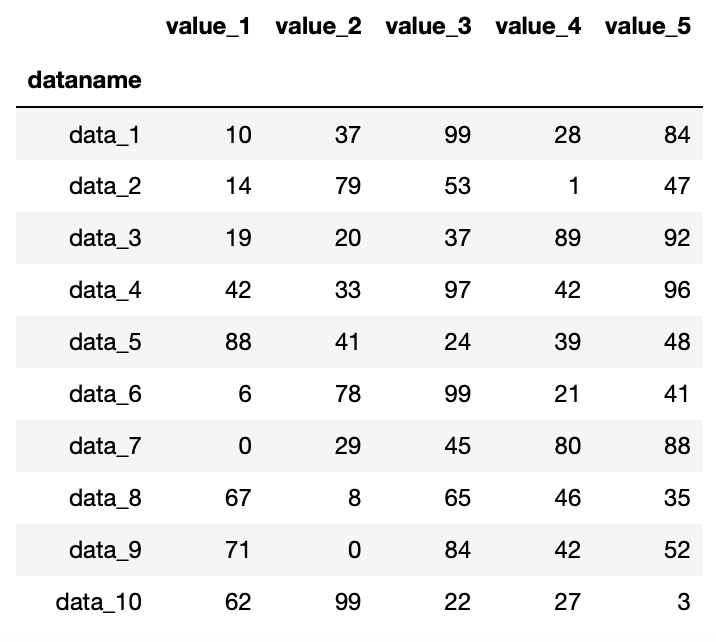
ということで今回は列を追加するassign、行を追加するappendに関して解説をしてきました。
新しいデータフレームとして作成できるというのが、前回解説した方法とは大きく違います。
元のデータフレームを汚したくない場合にいいかもしれませんね。
次回はデータフレームを連結する方法を解説していきたいと思います。
ではでは今回はこんな感じで。
コメント